最前
本篇将会简单介绍一下google的Mediapipe项目,并且使用它来做一些很简单的图像识别。“众”所周知,作者是个Javaer,Mediapipe是Python库,所以以下代码均在AI的帮助下编写,请注意辨别。
简介
通常都应该先介绍一下我们今天要用的工具,老规矩先嘀咕一小段,剩下的可以去官网看。我写的一定没有官网的介绍来的全,同样的,其余的功能也可以看官网介绍,google的文档写的还是不错的。
MediaPipe 解决方案提供了一套库和工具,可帮助您快速在应用中应用人工智能 (AI) 和机器学习 (ML) 技术。您可以立即将这些解决方案插入到您的应用中,根据需要对其进行自定义,并在多个开发平台上使用它们。MediaPipe 解决方案是 MediaPipe 开源项目的一部分,因此您可以进一步自定义解决方案代码,以满足您的应用需求。
github链接:https://github.com/google-ai-edge/mediapipe
google文档:https://ai.google.dev/edge/mediapipe/solutions/guide?hl=zh-cn
行动
首先我们需要借助几个库来做这件事情。
- opencv-python
- mediapipe
- numpy
然后我们就可以很方便的使用以下函数在视频中绘制人物骨架了:
# 主函数:播放视频并实时分析
def analyze_and_display(video_source=0):
cap = cv2.VideoCapture(video_source)
global paused
while cap.isOpened():
if not paused:
ret, frame = cap.read()
if not ret:
break
image_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
result = pose.process(image_rgb)
if result.pose_landmarks:
# 绘制骨架
mp_draw.draw_landmarks(frame, result.pose_landmarks, mp_pose.POSE_CONNECTIONS)
# 在循环内部处理每一帧时加入以下逻辑
original_height, original_width = frame.shape[:2]
# 设置缩放比例和最小高度
scale_percent = 50
min_height = 600
# 计算缩放后的尺寸
new_width = int(original_width * scale_percent / 100)
new_height = int(original_height * scale_percent / 100)
# 如果缩放后高度太小,则限制为最小高度并保持宽高比
if new_height < min_height:
new_height = min_height
new_width = int(original_width * new_height / original_height)
# 缩放图像
resized_frame = cv2.resize(frame, (new_width, new_height))
# 显示画面
cv2.imshow('Test', resized_frame)
cv2.setMouseCallback('Test', toggle_pause)
# 按 'q' 键退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
# 下载远程视频到本地临时文件
def download_video(url):
response = requests.get(url, stream=True)
fd, path = tempfile.mkstemp(suffix='.mp4')
with os.fdopen(fd, 'wb') as tmp:
for chunk in response.iter_content(chunk_size=1024 * 1024):
if chunk:
tmp.write(chunk)
return path
# 主函数入口
if __name__ == "__main__":
import sys
if len(sys.argv) != 2:
print("Usage: python squat_analyzer.py <video_file_or_url>")
sys.exit(1)
video_input = sys.argv[1]
if video_input.startswith(("http://", "https://")):
print("正在下载视频...")
video_path = download_video(video_input)
else:
video_path = video_input
result = analyze_and_display(video_path)
print(result)
这里多做了一步,可以在命令行中指定一个视频链接或者本地文件。另存这份python脚本,我们就可以使用命令行来分析指定的视频了。
效果如下:

可以看到,我们很容易就在视频中看到了人体骨架和各个重要关节点的位置,mediapipe的识别还是非常准确的,而且非常轻量化,对硬件的要求比较低。
那么拿到人体识别骨架图和关节点位之后,能做的事情就很多了,在官方文档中,每个点都有编号,如下:
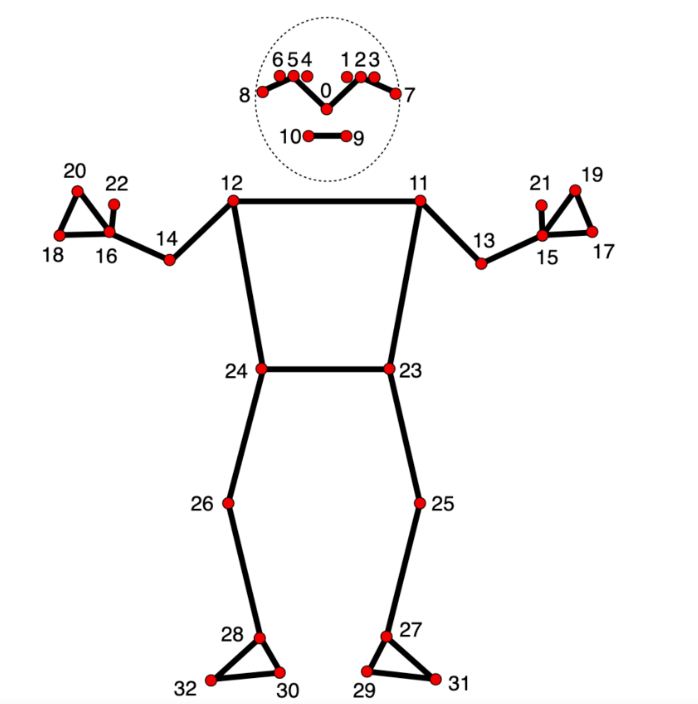
为了获得各个点的空间坐标,我们需要如下定义:
# 初始化MediaPipe Pose模块
mp_pose = mp.solutions.pose
pose = mp_pose.Pose(static_image_mode=False, model_complexity=1,
enable_segmentation=False, min_detection_confidence=0.5)
# 然后看analyze_and_display函数
image_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
result = pose.process(image_rgb)
if result.pose_landmarks:
landmarks = result.pose_landmarks.landmark
....
关于pose初始化参数的解释
STATIC_IMAGE_MODE:如果设置为 false,该解决方案会将输入图像视为视频流。它将尝试在第一张图像中检测最突出的人,并在成功检测后进一步定位姿势地标。在随后的图像中,它只是简单地跟踪那些地标,而不会调用另一个检测,直到它失去跟踪,以减少计算和延迟。如果设置为 true,则人员检测会运行每个输入图像,非常适合处理一批静态的、可能不相关的图像。默认为false。
MODEL_COMPLEXITY:姿势地标模型的复杂度:0、1 或 2。地标准确度和推理延迟通常随着模型复杂度的增加而增加。默认为 1。
SMOOTH_LANDMARKS:如果设置为true,解决方案过滤不同的输入图像上的姿势地标以减少抖动,但如果static_image_mode也设置为true则忽略。默认为true。
UPPER_BODY_ONLY:是要追踪33个地标的全部姿势地标还是只有25个上半身的姿势地标。
ENABLE_SEGMENTATION:如果设置为 true,除了姿势地标之外,该解决方案还会生成分割掩码。默认为false。
SMOOTH_SEGMENTATION:如果设置为true,解决方案过滤不同的输入图像上的分割掩码以减少抖动,但如果 enable_segmentation设置为false或者 static_image_mode设置为true则忽略。默认为true。
MIN_DETECTION_CONFIDENCE:来自人员检测模型的最小置信值 ([0.0, 1.0]),用于将检测视为成功。默认为 0.5。
MIN_TRACKING_CONFIDENCE:来自地标跟踪模型的最小置信值 ([0.0, 1.0]),用于将被视为成功跟踪的姿势地标,否则将在下一个输入图像上自动调用人物检测。将其设置为更高的值可以提高解决方案的稳健性,但代价是更高的延迟。如果 static_image_mode 为 true,则忽略,人员检测在每个图像上运行。默认为 0.5。
(以上,来自掘金:Mediapipe-前端机器学习之人体姿势检测)
这边获得的landmarks对象就可以获取各个点的坐标位置了,例如我们要获取右肩膀的数据:
print(landmarks[12])
附一下点位对应表:
0 - nose
1 - left eye (inner)
2 - left eye
3 - left eye (outer)
4 - right eye (inner)
5 - right eye
6 - right eye (outer)
7 - left ear
8 - right ear
9 - mouth (left)
10 - mouth (right)
11 - left shoulder
12 - right shoulder
13 - left elbow
14 - right elbow
15 - left wrist
16 - right wrist
17 - left pinky
18 - right pinky
19 - left index
20 - right index
21 - left thumb
22 - right thumb
23 - left hip
24 - right hip
25 - left knee
26 - right knee
27 - left ankle
28 - right ankle
29 - left heel
30 - right heel
31 - left foot index
32 - right foot index
打印到控制台发现,一个坐标点存在四个属性:
x: 0.615960717
y: 0.307109237
z: -0.115730092
visibility: 0.999980867
可以理解这是一个三维坐标以及坐标点的可见性。
那么有了这些点位坐标之后,我们自然而然就想到了可以通过计算两个坐标点之间的角度/距离来判断视频中人体的动作。这里就不展开了,可以自行发挥~
总结
实际体验下来,mediapipe是一个非常好上手的开源AI工具,并且在LLM的帮助下,写一些不熟悉的代码也还算能用,but有一些问题还是要自己解决,自己解决的过程中对成长也有所帮助。
参考了以下文章/项目,感谢: